
What is a service?
"Service" means something different to every team. Here's a precise definition, a litmus test, and a catalog schema, plus why AI agents make getting this right urgent.

“Agents magnify the DevOps & infra best practices you have, or the lack of practices you have.”
That’s what one of our customers told us recently and he’s a platform engineer at a Fortune 500 finance company. And the practice that trips up the most teams is how they define a “service” in their software catalog.
Is it a repo? A Kubernetes deployment? A business capability like “payments” or “checkout”? A Lambda function?
It may not seem like an issue, but once a company grows past a few teams, that ambiguity creates friction you can feel but can’t easily point to - like an incident where you don’t know who to page.
So if you don’t have an agreed-upon definition, it’s probably one of the most impactful things you can align on.
Here’s how we think about it:
How we define “service” at Port
The definition we’ve agreed on internally: a service is a deployable unit owned by a single team that exposes a stable interface to other systems.
Owned by a single team is clear, but what are deployable units and stable interfaces?
Deployable unit means that your team can change it, release it, and roll it back without requiring other teams to deploy their services at the same time.
Stable interface means that the way other systems interact with the service (API, events, etc.) changes slowly and backward-compatibly so consumers don’t break when the service evolves.
Quick litmus test: is it a service?
If you can answer yes to all of these, it’s probably a service:
Can you deploy it independently, without coordinating with another team?
If it goes down at 2am, is there one clear owner to page?
Can you roll it back without rolling back something else?
Does it have its own CI/CD pipeline (or a distinct stage in a shared one)?
And a few signs it’s not a service:
A shared library that other teams import (that’s a dependency, not a service)
A repo that contains three things deployed on different schedules (that’s three services, not one)
A Helm chart that bundles unrelated containers (that’s packaging, not a service)
There’s no true universal answer here and some companies might have multiple definitions of service internally (which is fine). The goal is getting to agreement in your engineering department so that your catalog, your on-call, and your scorecards all reference the same thing.
Best practices: what a service should look like in your catalog
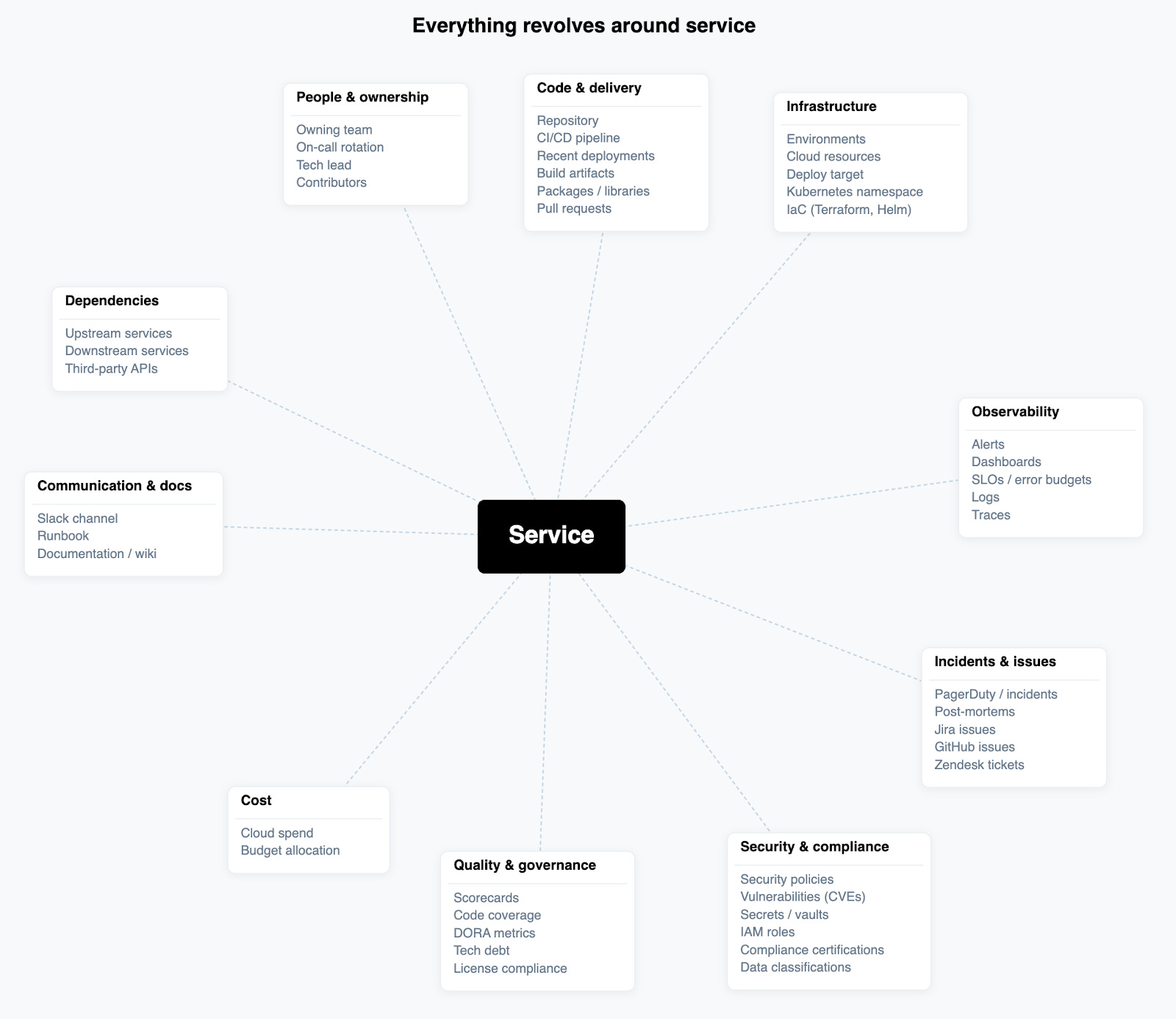
Once you've agreed on the definition, the next question is: what are the most important properties that a service should have, and what should it connect to?
Owning team: just one team (so you know who to turn to when something needs fixing)
Lifecycle stage: production, staging, deprecated, experimental (so humans and agents know what’s active and what to leave alone)
Tier/criticality: P0 revenue-critical vs. P3 internal tooling (drives SLO targets and incident response)
Language/framework: useful for scorecards and security scanning
Deploy target: where it runs (EKS cluster, Lambda, Cloud Run, etc.)
Repo: link to source (but remember: the repo is not the service)
Communication channel: link to Slack or Teams channel (so you or an agent knows where to page the owning team)
On its own, a service isn't worth that much. It needs to be connected to other things to be truly valuable.
Depends on: what other services does this call at runtime?
Consumed by: what other services rely on this service?
Owned by: Both a property and a connection to the owning team
The connections matter more than the properties. Without dependencies, you can't calculate blast radius. Without "Owned by" linked to a team with on-call data, incident routing breaks.
Defining a service matters more now than ever
Picture a P1 incident at 2am. A latency spike is hitting checkout. With a clean service definition, your on-call engineer opens the catalog, sees checkout-service, sees it depends on payment-gateway and cart-service, sees the owner is Team Payments, and starts debugging. The blast radius to other services is clear. The escalation path to senior engineers is clear. Time to action would be just minutes.
How to get started
Test if your services are services. Run each service through the litmus tests above. If you can deploy it independently and it’s owned by one team, it’s a service. If not, it may be a dependency, a sub-component, or multiple services bundled together.
Audit them against reality. Pull up a few recent incidents and compare what broke against what your catalog says. If the incident damaged three things the catalog calls one service, your definitions might be off.
Build the schema. Decide which core properties and relations are important to connect to your services. We recommend starting with owner, lifecycle, tier/criticality, and dependencies.
Make it the contract, company-wide. Once the definition and schema are agreed on, treat them like infrastructure. New services must be created from the template. Existing ones get migrated. If there are exceptions, they should get documented, not ignored.
You don't need a definition that covers every edge case. You need a shared one that's precise enough for both humans and agents to rely on.