
How does AI impact your role as a platform engineer?
Heads up: Developers are building agents. Lots of them. How do you as a platform engineer help them build while also staying in control?

Platform engineering’s goal has always been: make engineers more self-sufficient without sacrificing standards.
The best way to accomplish this was through self-service in a platform you controlled. When a developer needed a new service, they clicked a button and got a repo, a CI pipeline, monitoring, and a Dockerfile. You could let them do this because you built in engineering standards. That combination of self-service and standards was a win-win for you and your developers. They got velocity, you got control.
With AI, developers became builders of agentic workflows. By building agents, they can automate large parts of their jobs. They’re building SRE agents, release agents, skills, etc. They already got permission to use all these AI tools, so they started to stitch stuff together.
What you get is lack of governance & visibility into agents that are taking destructive operations without human oversight.
We call this agent sprawl.
So what does that mean for you as a platform engineer?
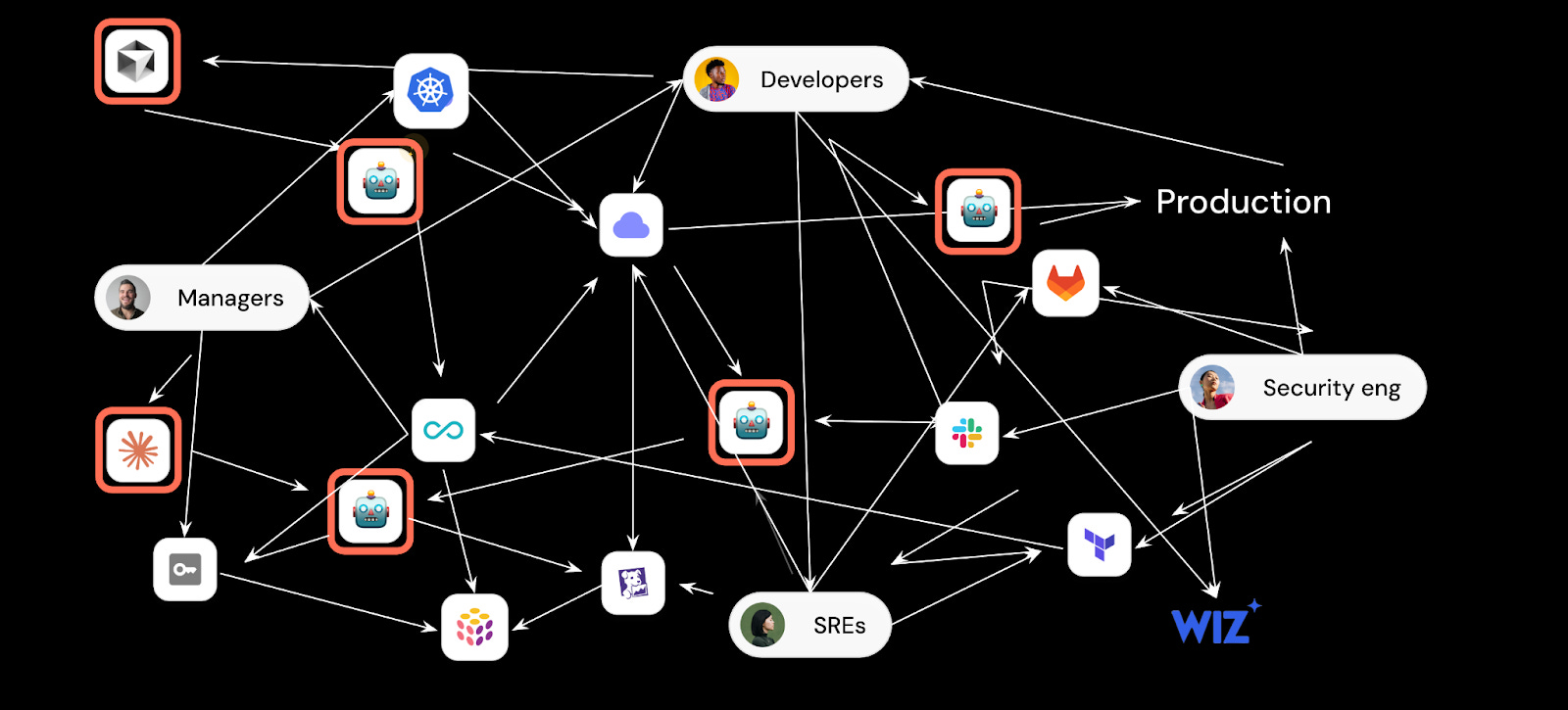
How should you think about the relationship between you and developers?
As platform engineers in an AI world, of course you want developers to use AI more. But every time adoption of technology goes up, so does the demand for everything you’re responsible for like costs and governance.
There’s also something uncomfortable about being bypassed by the people you were supposed to enable. You take pride in making developers more capable with your help, but now they’re building agents themselves.
AI has given developers the power to build anything that will automate their work like an SRE agent, deployment agent, or even a basic catalog that helps their agents work.
To make their agents powerful, they want to feed these agents with real actions & access to real data. To do that, they still have to go through you. But even without the actions and context lake you provide, they can still create things that are powerful enough to be dangerous.
Let’s say an engineering team builds themselves an SRE agent without going through you. We can even go a step further and say that it works really well in its task of triaging the issue, saving the team hours per incident.
But what does the agent probably not do?
It probably doesn’t leave an audit trail.
It probably isn’t being respectful of PII.
It probably doesn’t use appropriate credentials to get data.
And the list goes on.
What the team definitely didn’t do is build the agent with the standards their company expects from the start.
And why would they? They have a real, immediate need and AI makes it easy to solve. They’re also feeling the pressure of producing more results by engineering leadership.
Developers shouldn’t have to wait. (And they’re not going to)
With this new tool and the new urgency, they’re just doing their jobs in a new way, primarily doing two things:
They’re using MCP to query data and get insights that help them or their agents work.
They’re building agents like SRE agents that are getting more capable, taking on more responsibilities across the SDLC.
Developers (and agents) getting the data they need can be solved in a scalable way by providing a rich context lake.
But when all engineers start building agents, how do you facilitate that in a scalable way?
The product management side of platform engineering
Given the new reality we’re all living in, platform teams have three options.
You can do nothing and let developers build agents however they want. The agent sprawl is already here anyway, so why fight it? The problem is you end up with no visibility, no standards, and no way to intervene when something goes wrong (and it will).
You can mandate that all AI development flows through the platform team. You can probably expect a revolt if you choose this route because the tools are already in developers’ hands. Cursor runs locally. Claude Code runs locally. This is a good way to slow down engineering, not speed it up.
Finally, and I think this is the only option that will actually work, you can make the platform compelling enough that developers actively choose to build agents with it.
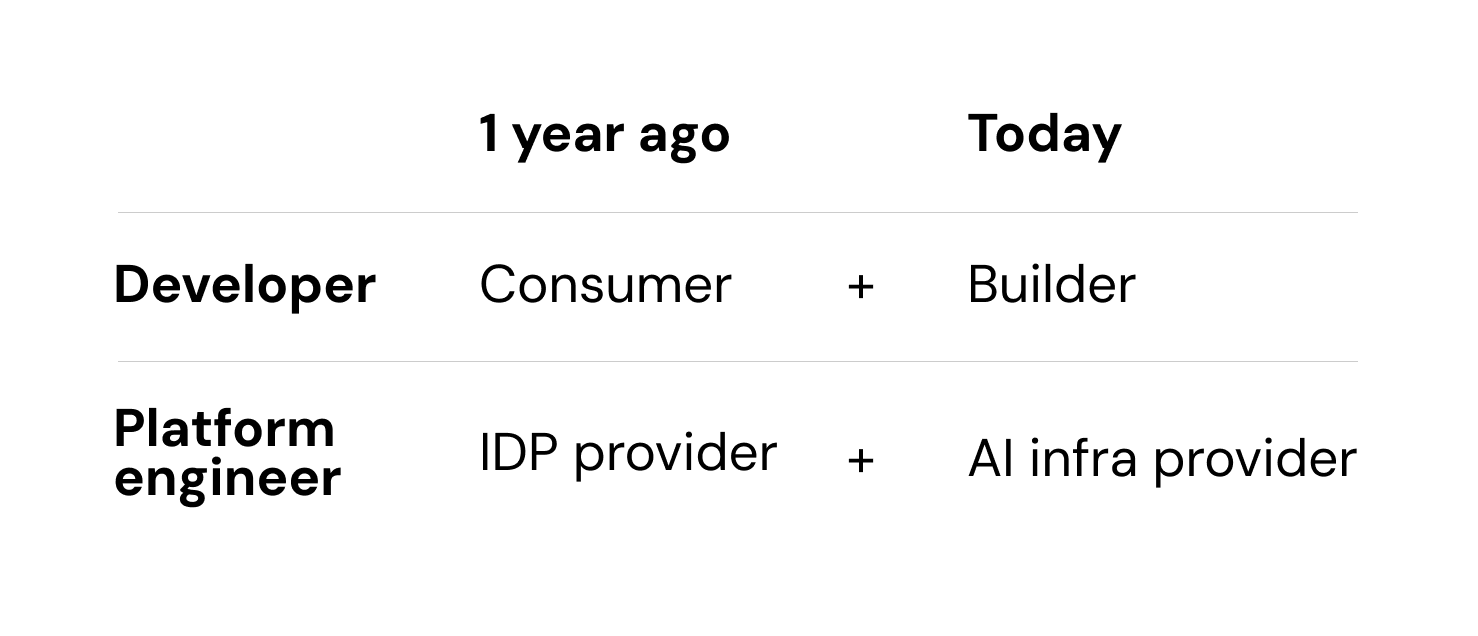
So how do you make it more compelling?
This is what I like to call the product management side of platform engineering. You first need to understand what developers are actually trying to do, then remove the hardest parts of it.
I’ll let you do the work in your org of talking to developers and finding out what they find difficult when building agents.
But I’ll also give you a look into what I see as some of the common denominators because developers building agents hit the same walls every time. Scattered data, wild integration connections, lack of approval gates (or too many), or too much access to critical systems, to name a few.
I see those issues repeat themselves across all agents at the “kicking the tires” stage. But, if you succeed in removing some of that friction or at least minimizing it, you’ll have a much higher chance that developers will create agents that don’t end up hitting those walls.
There’s also something else here. Developers who build something useful want others to benefit from it, just like in open source. If there’s a place to share the incident triage skill their team built, they’ll put it there. If there’s a registry where others can find it and extend it, it gets better over time. The platform becomes the place where good work accumulates.
That’s what makes a platform compelling. When developers feel they are using an experience that was designed for them (and their agents).
How do you create a compelling agent-building experience for your engineering team?
Now that your developers are agent builders, one of your jobs is to make that experience as seamless and enjoyable as possible. They’re coming to make something new. That’s a creator experience, and it requires a different kind of thinking. This is DevEx 2.0.
Here’s what I think matters most when you’re designing for builders:
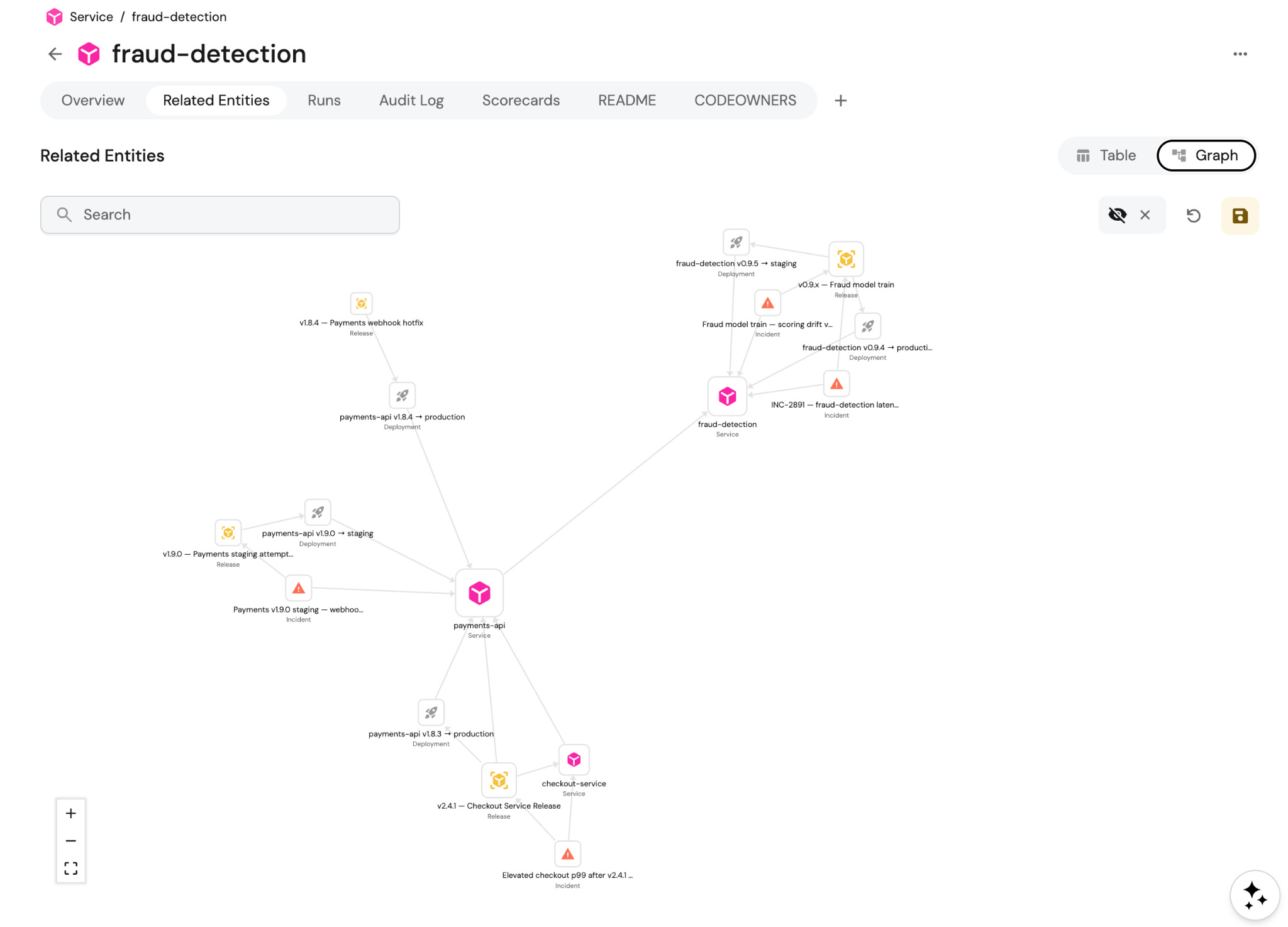
They need to know what’s available to them before they start. A developer sitting down to build a release management agent shouldn’t have to ask around to find out what data they can access, which integrations exist, or what actions are possible. That discovery has to be seamless.
They need early wins. The fastest way to get a developer invested in your platform is to get them to something working quickly. Starter templates, example workflows, pre-built skills are all great places for them to start forking. A developer who gets something running in an hour is far more likely to build the real thing on your platform than one who spent the first day figuring out how to authenticate.
They need to see what others have built. This is the open source side of things that developers love. Developers who build something useful want to share it, and developers starting from scratch want to see what already exists. A skill registry or agent catalog will make them feel that the platform is alive. When a developer can browse what their colleagues built and extend it, the platform stops feeling like infrastructure and starts feeling like a community.
Let’s expand on helping your team discover what’s available before they start building agents.
What building blocks should you give them that their agents will need?
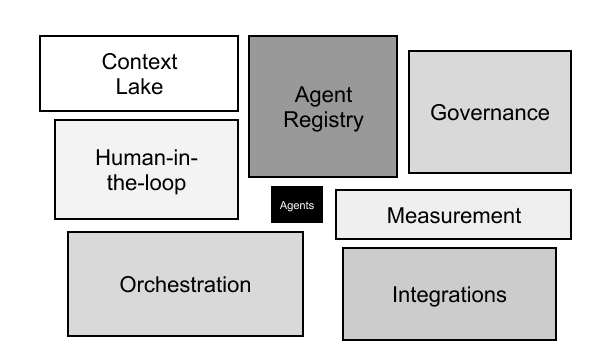
I wrote previously about the “Hidden tech debt of agentic engineering” where I expanded on the 7 blocks of tech debt every demo agent creates
A reliable context lake. Agents need to know things in real time and that information needs to be accurate: who owns this service, what changed in the last deploy, what this service depends on, who’s on call right now.
Without this, a team building their own agent spends more time on data plumbing than on the actual logic and gets access to data they wouldn’t be able to access without it. The platform team pulls it into one place, keeps it fresh, and exposes it through an API or MCP that any agent can query.
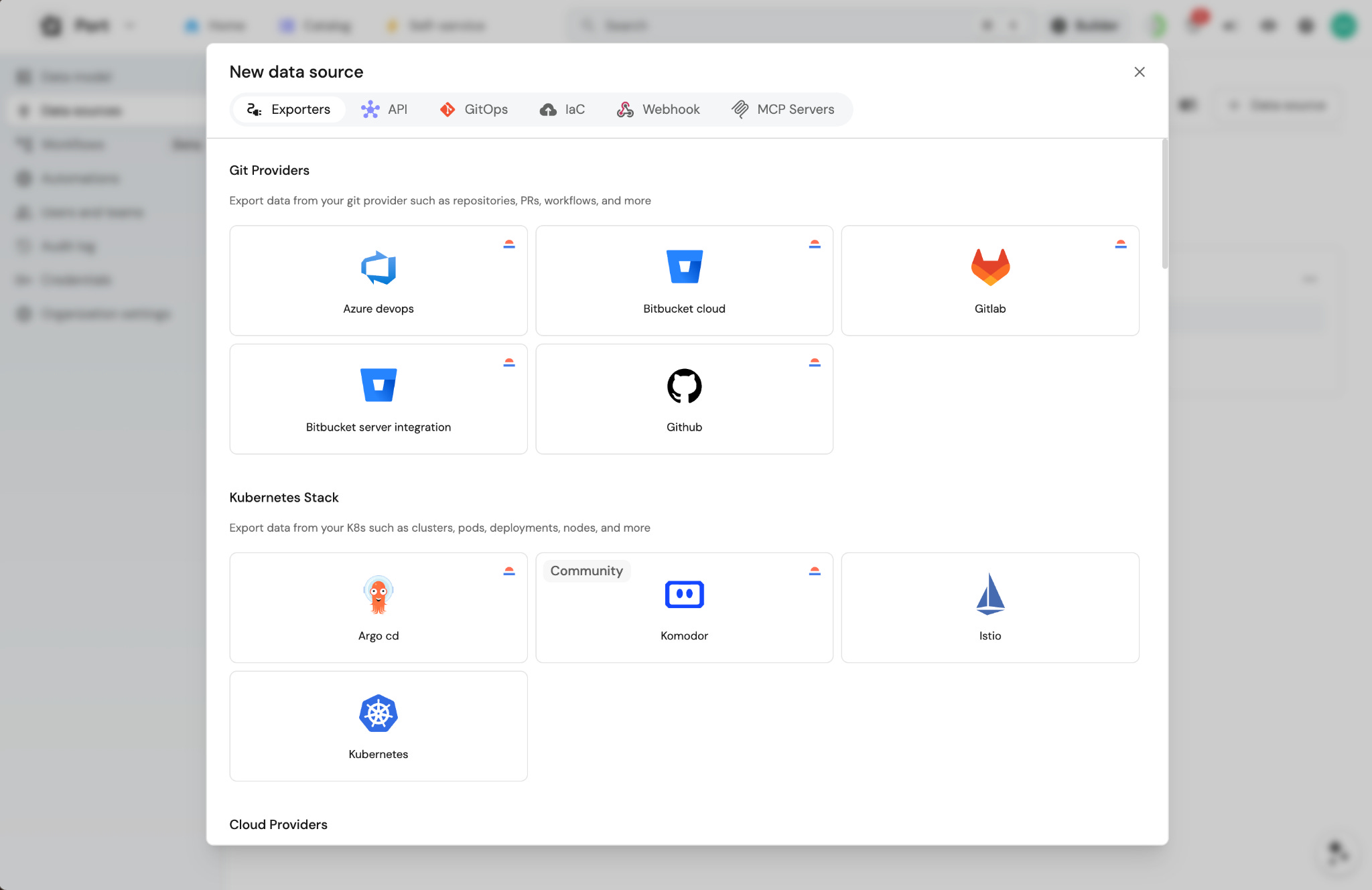
Pre-cleared integrations. Agents need to talk to systems: GitHub, PagerDuty, Datadog, Jira, your cloud provider. Getting access to each of those is a process. Developers building agents on their own may go through that process independently. By centralizing it, the platform team clears the integrations once and every agent gets them.
A menu of approved, governed actions. Agents don’t just read. They do things: trigger rollbacks, open PRs, restart pods, close incidents. Teams building agents on their own either avoid actions entirely (so the agent just tells you what to do) or wire them up without guardrails. The platform team defines which actions are available as tools, so the question is never “can this agent do this?” but “did we explicitly allow it to?”
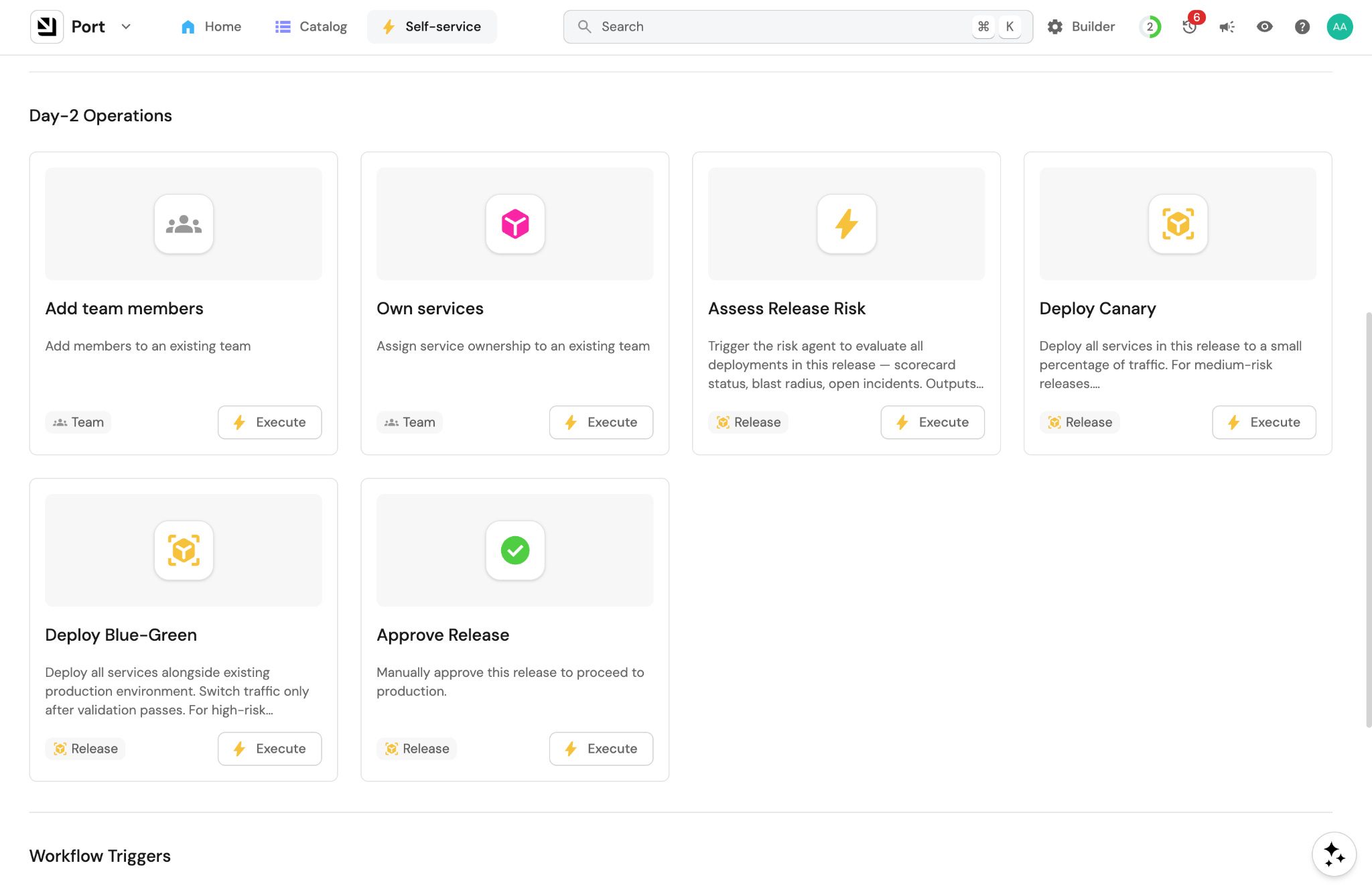
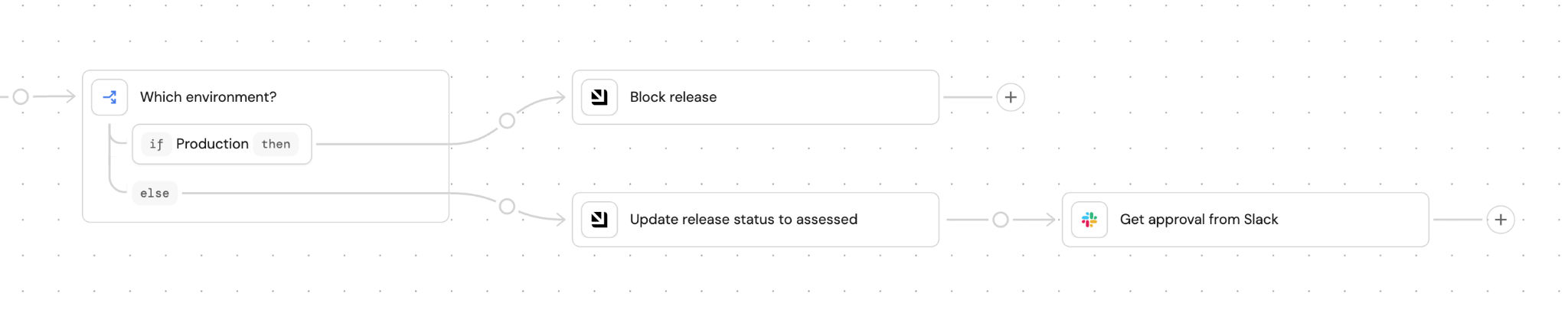
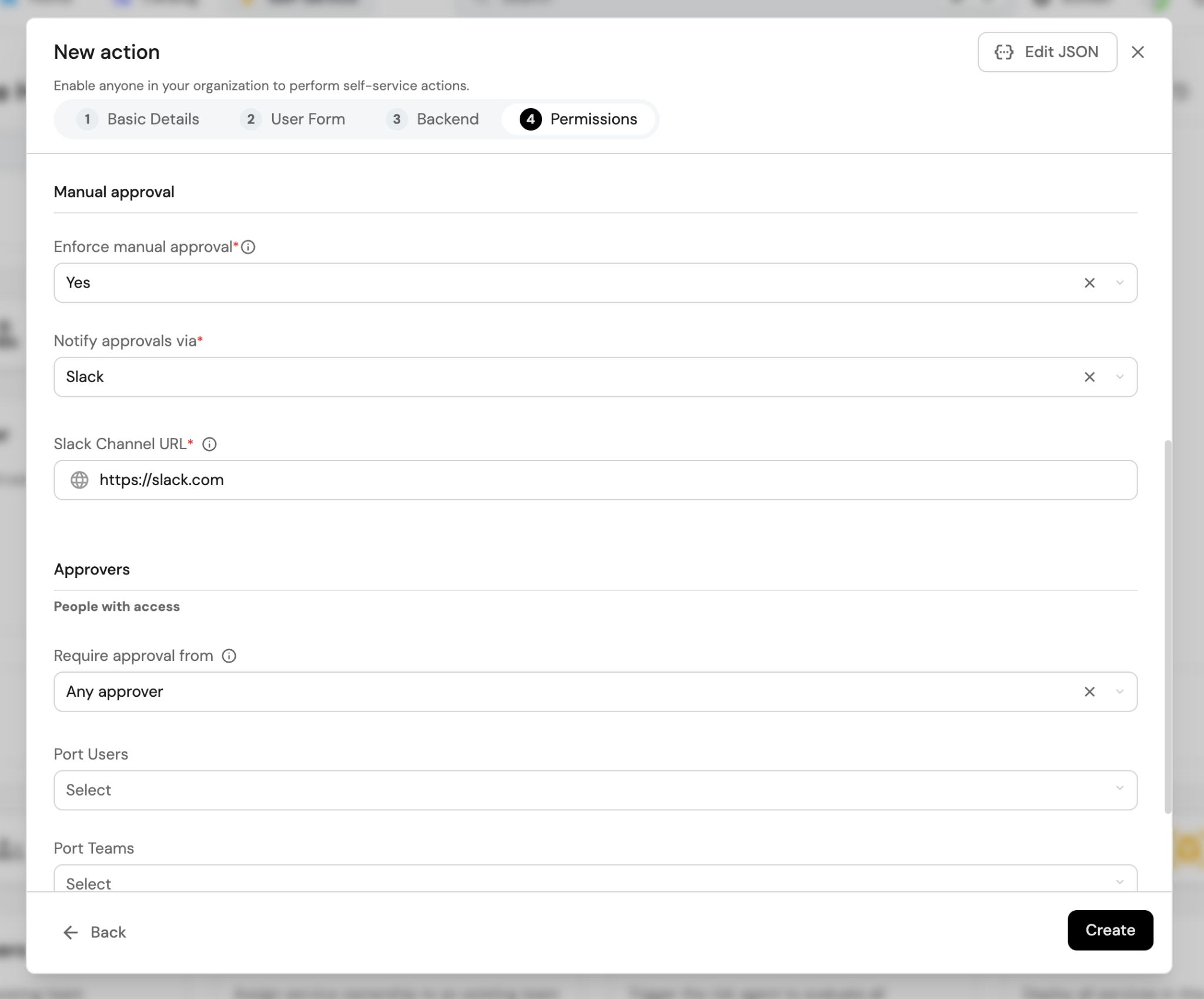
Deterministic policies. An agent that suggests a production rollback is fine. An agent that triggers one at 2am without waking anyone up is not. You can’t handle that with a prompt or skill like “Please ask before doing anything in production”. Policies must be encoded as gates: staging auto-approves, production requires human sign-off outside business hours. They either pass or they don’t and they need to be deterministic.
An audit trail. When something goes wrong at 3am, you need to know what the agent did, what data it accessed, what triggered it, and what the outcome was. Teams building their own agents almost never add logging upfront. It feels like overhead at first. The platform team needs to build audit logging into the workflow engine so it’s automatic. Every action is on the record whether anyone thought to ask for it or not. The added benefit of the audit trail is that it also serves as the decision trace that will help agents improve over time.
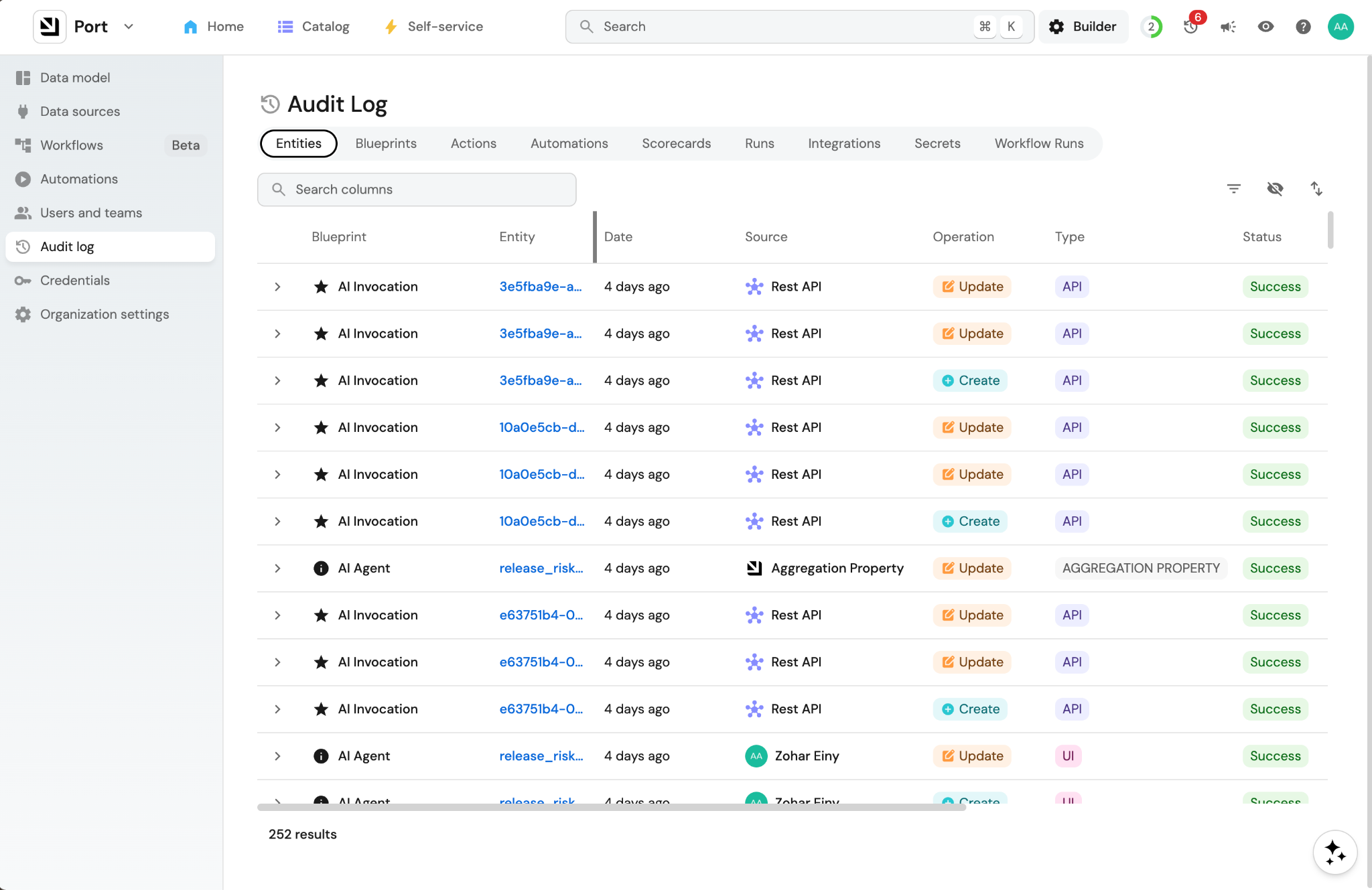
A review process. Taking an agent from demo to production requires someone from platform to check permissions, test edge cases, and define what production-ready actually means. The platform team must own that lifecycle: from experiment, to reviewed, to trusted, to fully autonomous.
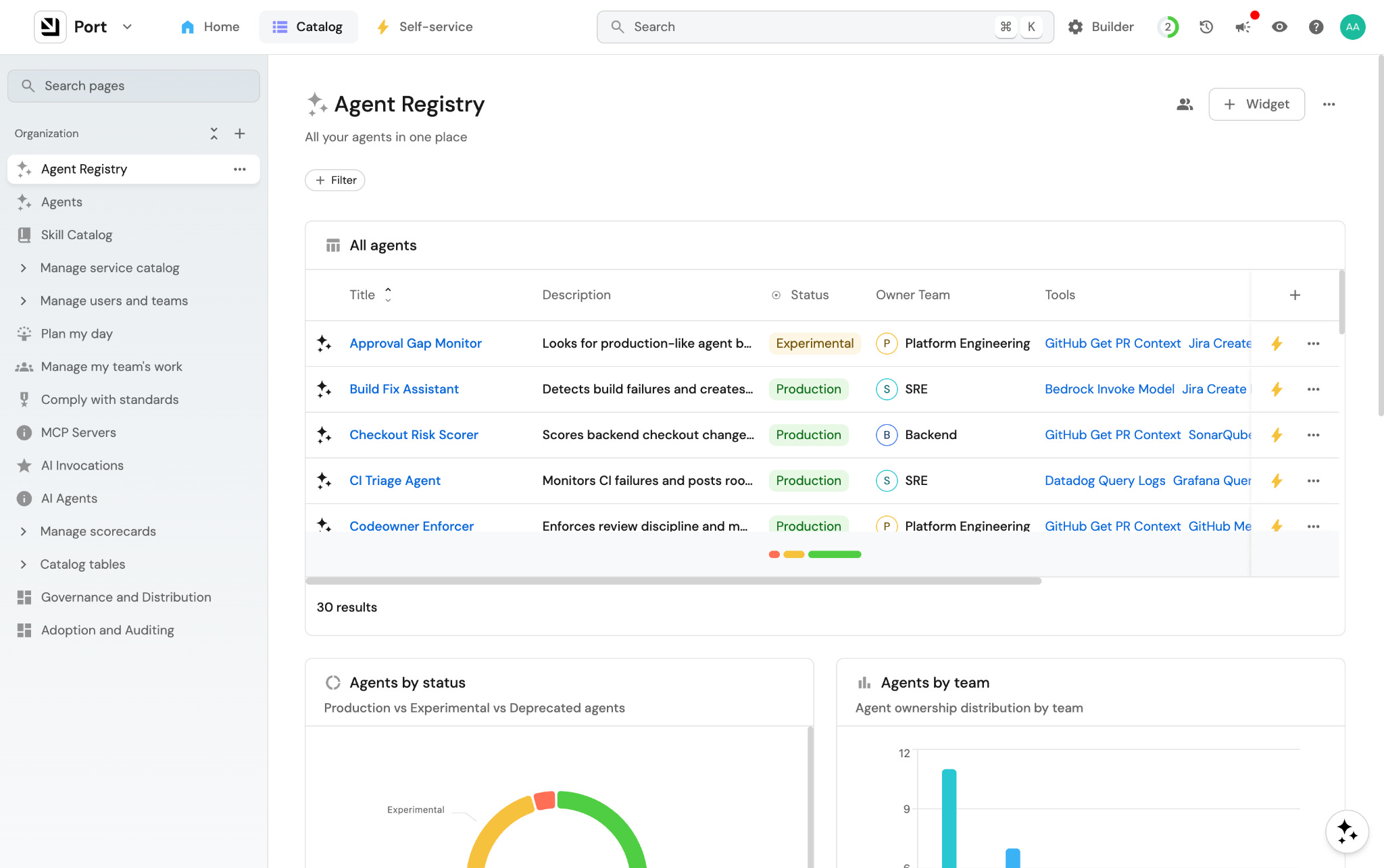
An approval or human-in-the-loop layer. At some point every agent needs to stop and ask a human. Teams building their own approval logic get this wrong in different ways. Some hardcode a Slack message, some skip it entirely. None of them share a model, so when agents need to work across teams, the approval logic breaks at the seam. The platform provides one: these actions auto-approve, these require a human, this is who gets notified. A team that builds on it doesn’t have to think about any of that.
None of these are complicated on their own. But when every engineer is building their own agents, the problem compounds quickly.
The surface area grew
The ground is shifting and your old job didn’t go away. The service catalog still needs maintaining. The golden paths still need updating. The CI/CD integrations still break.
And now on top of all of that, there are agents running in the org that you didn’t build, accessing systems you provisioned, doing things you can’t fully see. The surface area of what you’re responsible for grew, but nobody took anything off your plate to make room.
Just because you don’t have a monopoly anymore doesn’t mean you’re not relevant. You’re actually about to become relevant than ever before. Because developers aren’t waiting and the number of agents is exploding. And the window where the number of agents in your org is still small enough to get ahead.
We talked about a win-win situation for platform engineers and developers. I believe both teams can still achieve a win-win while using AI.
Port is built for platform engineers stepping into this new role who want to build a win-win experience. It gives your team the foundation to give developers the building blocks they need in their new builder role: governed data, pre-cleared integrations, approved actions, approval gates, and more.
Every engineer is a builder now. It’s time for platform to build for them while staying in control.